We’re excited to announce the Fiddler and Databricks integration! Together, we’re helping companies accelerate the production of AI solutions as well as streamlining their end-to-end MLOps experience.
Simplify the MLOps workflow with Fiddler and Databricks
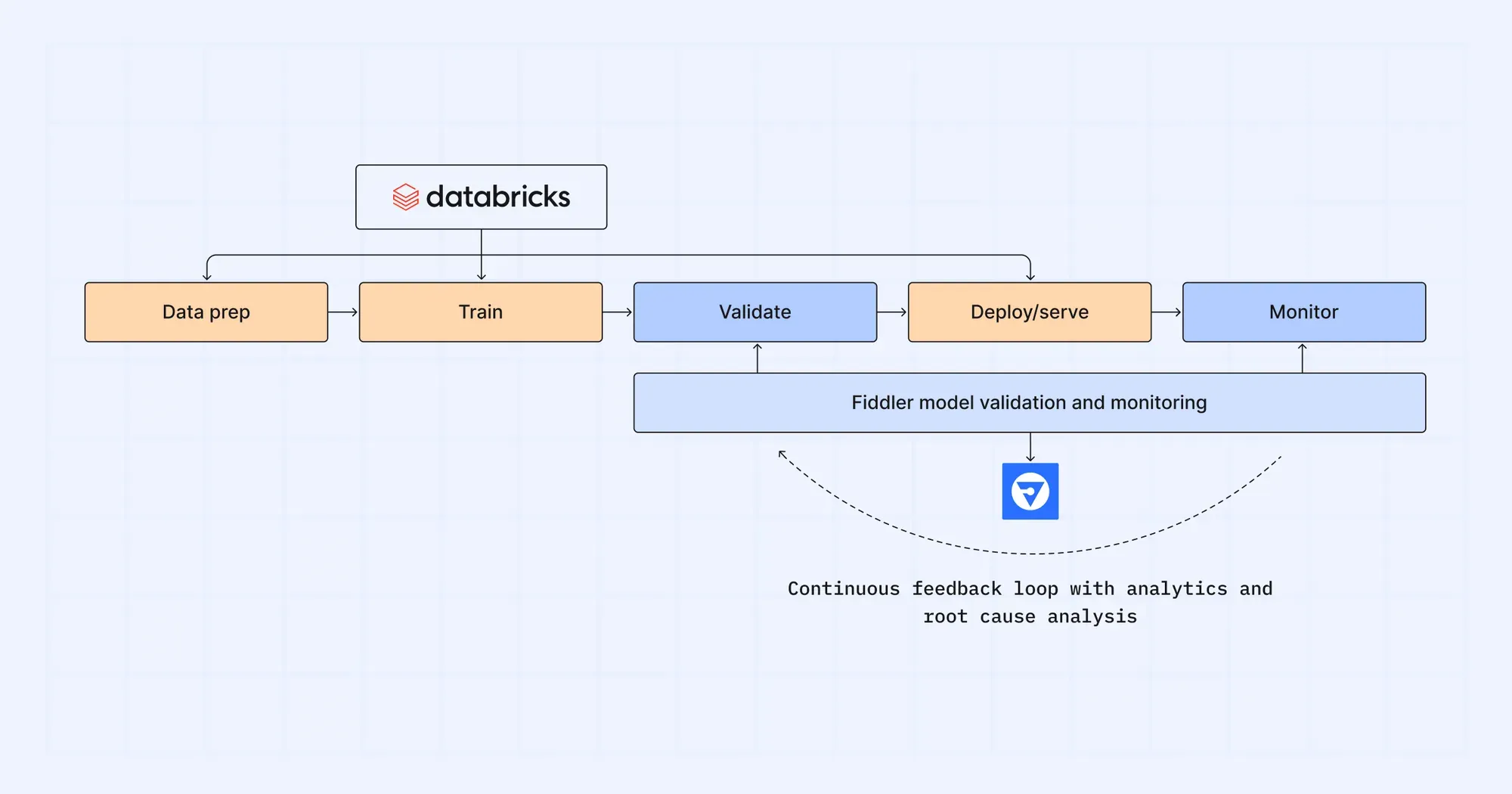
When Fiddler and Databricks are used together, ML teams simplify their MLOps workflow and create a continuous feedback loop between pre-production to production to ensure ML models are fully optimized and high performing. Data scientists can explore data and train models in the Databricks Lakehouse Platform and validate them in the Fiddler AI Observability platform before launching them into production. Fiddler monitors production models for data drift, performance, data integrity, and traffic behind the scenes, and alerts ML teams as soon as high-priority model performance dip.
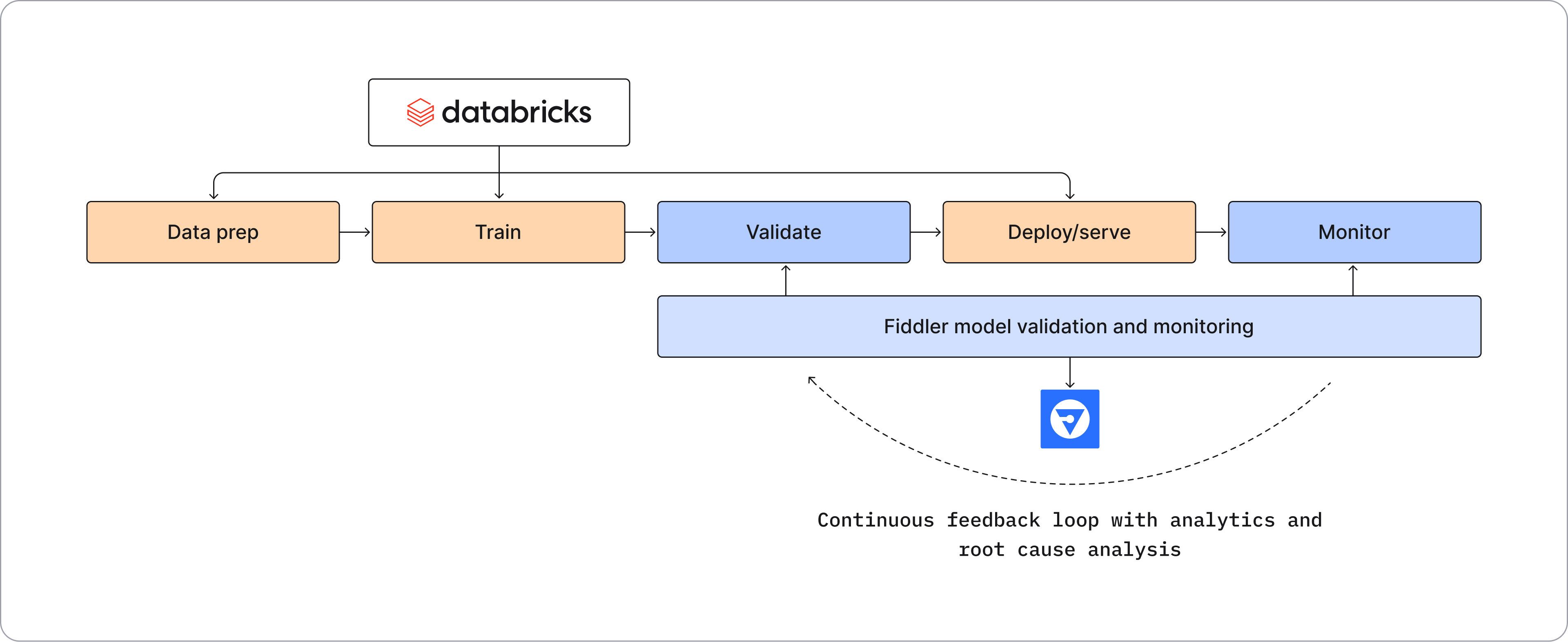
Fiddler goes beyond measuring model metrics by arming ML teams with a 360° view of their models using rich model diagnostics and explainable AI. Contextual model insights connect model performance metrics to model issues and anomalies, creating a feedback loop in the MLOps workflow between production and pre-production. ML teams can confidently pinpoint areas of model improvement, and go back to earlier stages of the MLOps workflow as early as data exploration and preparation, in Databricks, to explore and gather new data for model retraining.
Get started with Fiddler in minutes
Install and initiate the Fiddler client to validate and monitor models built on Databricks in minutes by following the steps below or as described in our documentation:
1. Upload a baseline dataset
Retrieve your pre-processed training data from a Delta table. Then load it into a data frame and pass it to the Fiddler:
baseline_dataset = spark.read.table("YOUR_DATASET").select("*").toPandas()
dataset_info = fdl.DatasetInfo.from_dataframe(
baseline_dataset,
max_inferred_cardinality=100)
fiddler_client.upload_dataset(
project_id=PROJECT_ID,
dataset_id=DATASET_ID,
dataset={'baseline': baseline_dataset},
info=dataset_info)2. Upload model metadata
Share model metadata: Use the ML Flow API to query the model registry and signature which describes the inputs and outputs as a dictionary:
import mlflow
model_uri = MlflowClient.get_model_version_download_uri(model_name, model_version)
mlflow_model_signature = mlflow.models.ModelSignature.to_dict(model_uri)Now you can share the model signature with Fiddler as part of the Fiddler <code>ModelInfo</code> object :
model_info = fdl.ModelInfo.from_dataset_info(
dataset_info = fiddler_client.get_dataset_info(YOUR_PROJECT,YOUR_DATASET),
target = "TARGET COLUMN",
#optionalArguments
mlflow_params = fdl.MLFlowParams(mlflow_model_signature))
fiddler_client.add_model(
project_id="Your Project ID",
dataset_id=DATASET_ID,
model_id="Your Model ID",
model_info=model_info)3. Publish events
Live models: Publish every inference format and send every model output as a dataframe to Fiddler using the <code>client.publish_event()</code>
fiddler_client.publish_event(
project_id=PROJECT_ID,
model_id=MODEL_ID,
event=my_event,
event_timestamp=xxxxxxxxxxx)Batch models: Use the data change feed on live tables and put the new inferences into a data frame:
changes_df = spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingVersion",last_version) \
.option("endingVersion", new_version) \
.table("inferences").toPandas()
fiddler_client.publish_events_batch(
project_id=PROJECT_ID,
model_id=MODEL_ID,
batch_source=changes_df,
timestamp_field='timestamp')Contact our AI experts to learn how enterprises are accelerating AI solutions with streamlined end-to-end MLOps using Databricks and Fiddler together.