Model Monitoring for Enterprises






Accelerate ML Monitoring and Model Deployment
Want to decrease time-to-production and increase the number of models you release? How about resolving ML model issues quickly so you can achieve faster time-to-market?
The centralized dashboard delivers deep insights into model behavior and uncovers data pipeline issues to save debugging time. The Fiddler AI Observability and Security platform operates at enterprise scale so you can go to market faster by monitoring and validating models during pre-deployment phases and releasing them in production.
- Catch and fix model inference violations right when they happen.
- Detect outliers and quickly assess which ones are caused by specific model inputs.
- Pinpoint data drift and contributing features to know when and how to retrain models.
Reduce Costs with Scalable Machine Learning Monitoring Tools
Adopting enterprise-scale model monitoring tools eliminates the ongoing costs of building and managing an in-house ML monitoring solution. More importantly, it saves engineering and data scientists’ time so they can focus on what they do best: building ML models.
Reducing errors saves money, and delivering high-performance models to customers increases satisfaction and referrals.
- Lower costs by reducing the mean time for issue identification and resolution (MTTI and MTTR).
- Decrease the number of errors to save money and engineering time.
- Grow revenue by increasing the number of models put in production in less time.
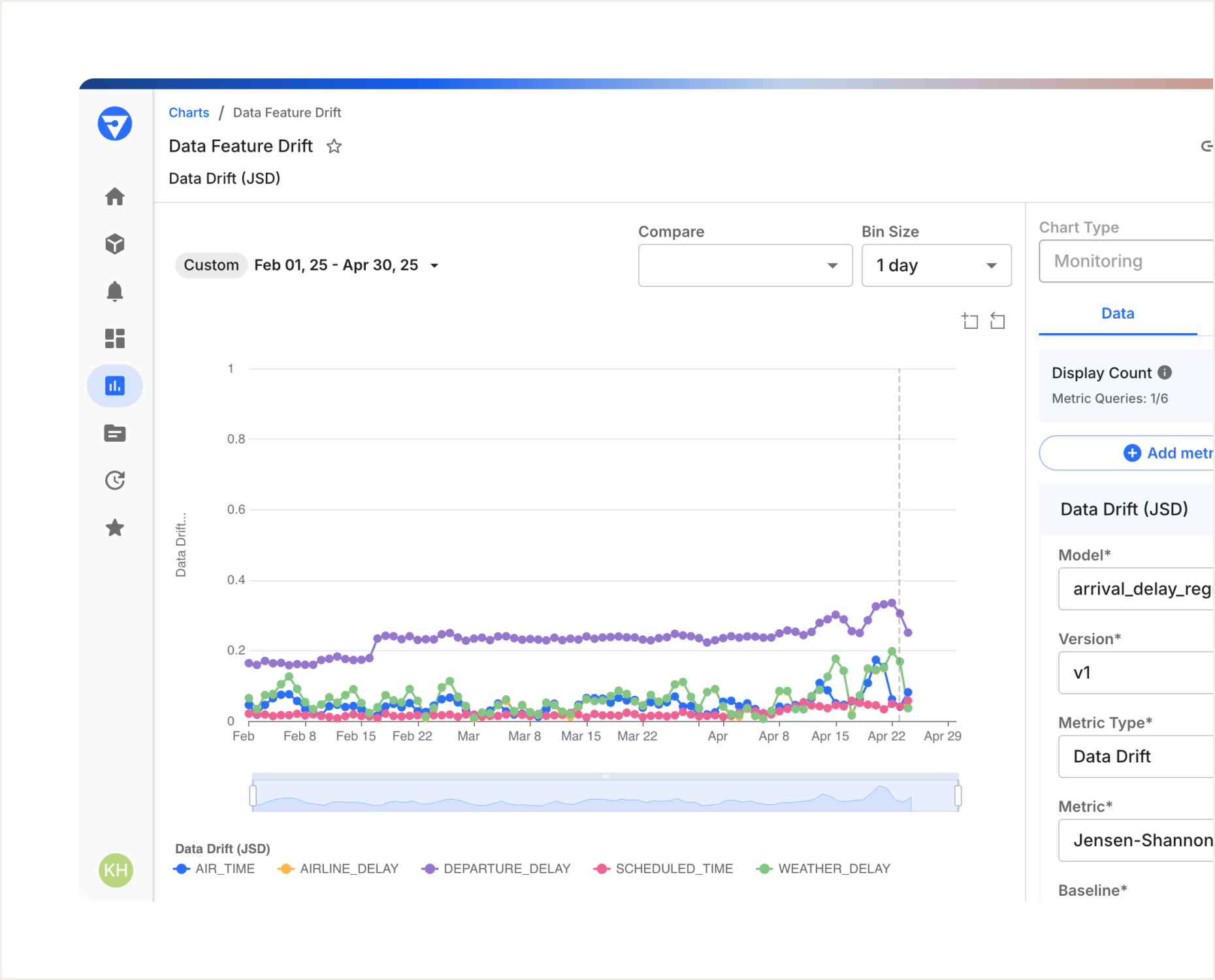

Unify Teams with Collaborative ML Model Monitoring
If you have process silos and disparate monitoring solutions, you are at risk of operational inefficiencies, not to mention losing out on the full benefits of collaboration. A centralized ML model monitoring framework helps eliminate these gaps by bringing teams together around a shared source of truth.
Monitor all training and deployed models in one place for streamlined detection of data changes. The Fiddler Observability and Security platform empowers teams to collaborate, discover, discuss, and resolve issues faster through a unified MLOps monitoring platform.
- Deliver a common platform with defined terminology to work across different MLOps teams.
- Enable multiple teams to work on and use a single model simultaneously.
- Provide a unified dashboard with shared insights and custom real-time alerting.
- Optimize business outcomes by connecting model performance metrics to business KPIs.
Model Monitoring Features for ML Systems
Featured Resources
Frequently Asked Questions
What is ML model monitoring?
ML model monitoring is the continuous tracking of machine learning models to assess performance, detect anomalies, and ensure reliability.
Why is monitoring machine learning models important?
Monitoring ML models is crucial to ensure they perform as expected in real-world conditions. It helps identify issues like data drift, bias, and model degradation to maintain accuracy over time.
What are the best practices for ML model monitoring?
Best practices include setting clear performance benchmarks, implementing real-time monitoring, regularly retraining models, and integrating automated alerts. Ensuring data quality and explainability also enhances monitoring effectiveness.
What metrics should be tracked in ML model monitoring?
Key metrics include accuracy, precision, recall, F1-score, AUC-ROC, data drift, model drift, latency, and error rates. Monitoring these ensures model reliability and helps detect potential performance declines.
How does ML model monitoring support AI governance?
Continuous monitoring provides transparency into model decision-making, ensuring accountability and compliance with ethical guidelines. It helps organizations maintain responsible AI practices and align with governance frameworks.
How can businesses measure the ROI of ML model monitoring?
Businesses can measure return on investment by tracking improvements in model accuracy, reduced downtime, operational efficiency, and risk mitigation.
