Fiddler Auditor: The Open Source Robustness Library for Red-teaming of LLMs
Learn about Fiddler Auditor, the open source robustness library that facilitates red teaming of LLMs. Improve LLMs and minimize hallucinations by testing for robustness, correctness, safety, and bias before deploying your LLMs to production.
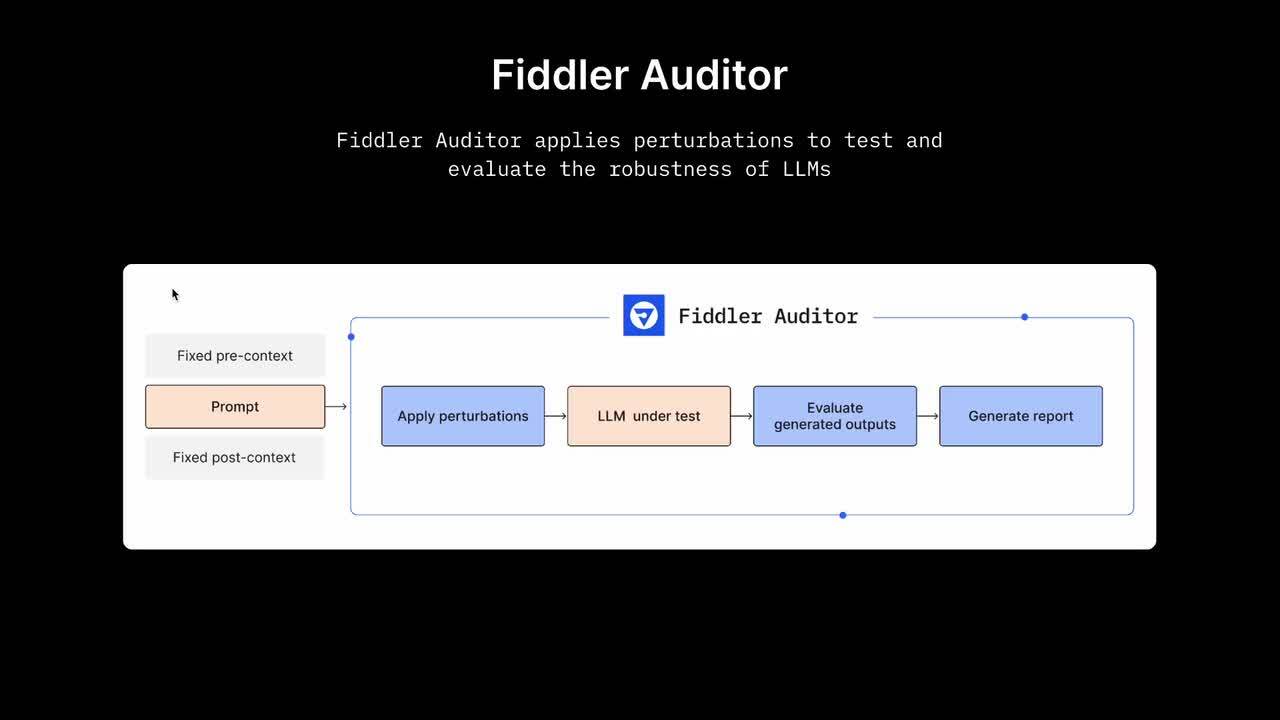
[00:00:02] Fiddler Auditor is the open source robustness library that facilitates red-teaming of large language models. Different large language models can have different robustness scores, so comparing the robustness of prompts across versions or large language model providers can help you select the best model for your use case.
[00:00:18] Robustness testing is a critical step in pre-production to minimize hallucinations, bias and adversarial attacks.
[00:00:25] Now let's dive into how Fiddler Auditor works. Let's consider a case where you are evaluating the robustness of certain prompts. You want to set a fixed pre-contact, so the large language model has a specific instruction, like "please give me precise answers or be truthful."
[00:00:39] Then you also want to set a fixed post-context, which could be another instruction, like "provide the output in JSON format."
[00:00:46] Once those are set, you can evaluate the prompt by putting it in a question or paragraph and apply perturbations. Why apply perturbations? In language you can convey the same meaning in many different ways, which has its own challenges.
[00:00:59] Once your large language model is in production, users will ask the same questions in slightly different ways. So you want to evaluate your large language model under different types of perturbations.
[00:01:08] Once you apply perturbations to your model, you can evaluate the generated outputs using custom evaluation logic.
[00:01:15] You can generate a report with robustness scores for each prompt to gain insights and improve prompt engineering by evaluating techniques like few-shot prompting to enable in-context learning and chain-of-thought to address complex tasks like common sense reasoning and arithmetic to steer the model for better performance.
[00:01:30] Check out the Fiddler Auditor in the GitHub repo.
[00:01:33] Give us a star if you like it, and feel free to contribute.
