Quicktour: Monitor NLP and LLM-based Embeddings for Data Drift
Learn how Fiddler’s unique, clustering-based method accurately monitors data drift in NLP models and LLM-based embeddings.
[00:00:00] NLP models and LLM-based embeddings are prone to performance degradation due to data drift, which can negatively impact organizations and our customers. Fiddler offers a unique clustering-based method to accurately monitor data drift in NLP models and LLM-based embeddings. This approach finds dense regions of a high dimensional space and tracks shifts in the distribution of such regions and production. The drift value is then reported in standard distributional distance metrics such as Jensen-Shannon Divergence or Population Stability Index.
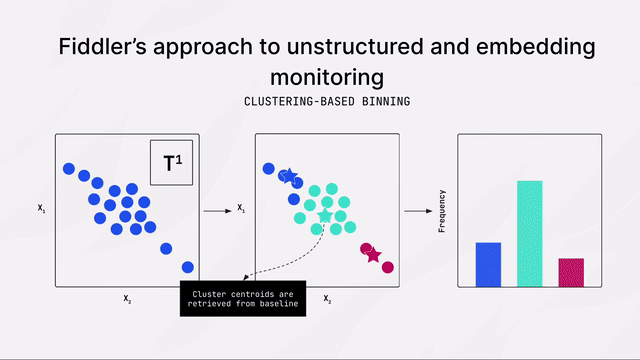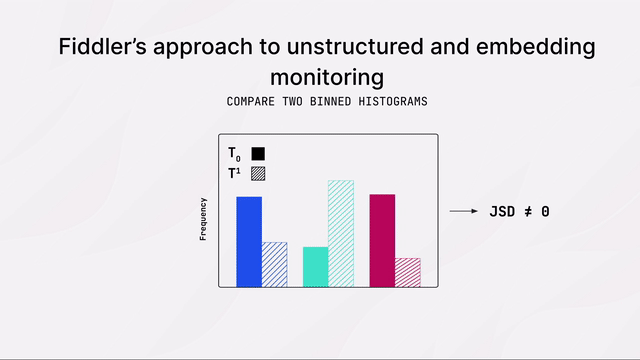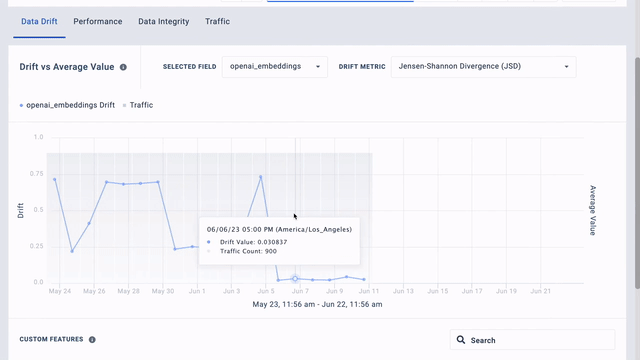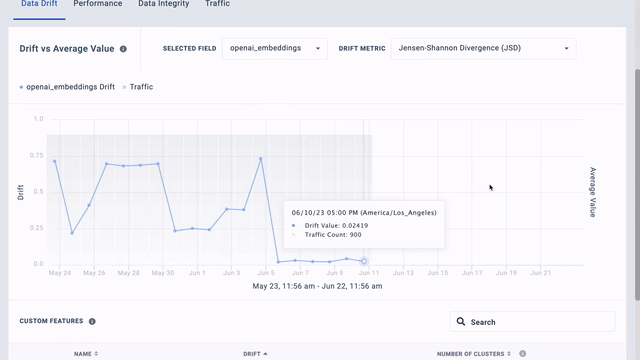
[00:00:31] Here we monitor data drift and embeddings of the 20 newsgroups dataset generated by OpenAI. We created the baseline data by uniformly sampling five general subgroups at random.
[00:00:42] Spikes in the drift chart show drift from specific subgroups in different time intervals.
[00:00:46] You can compare the baseline and production data distribution and analyze bins with high drift to gain insight into the data and assess whether the model needs to be retrained or tuned.
[00:00:56] You can proactively stay ahead by setting real-time alerts on high priority issues. You can also create custom reports and dashboards to track the health of language models.
[00:01:06] Request a demo or contact us for a deep dive with our data science team.
