AI has been in the limelight thanks to recent AI products like ChatGPT, DALLE- 2, and Stable Diffusion. These breakthroughs reinforce the notion that companies need to double down on their AI strategy and execute on their roadmap to stay ahead of the competition. However, Large Language Models (LLMs) and other generative AI models pose the risk of providing users with inaccurate or biased results, generating adversarial output that’s harmful to users, and exposing private information used in training. This makes it critical for companies to implement LLMOps practices to ensure generative AI models and LLMs are continuously high-performing, correct, and safe.
The Fiddler AI Observability platform helps standardize LLMOps by streamlining LLM workflows from pre-production to production, and creating a continuous feedback loop for improved prompt engineering and LLM fine-tuning.
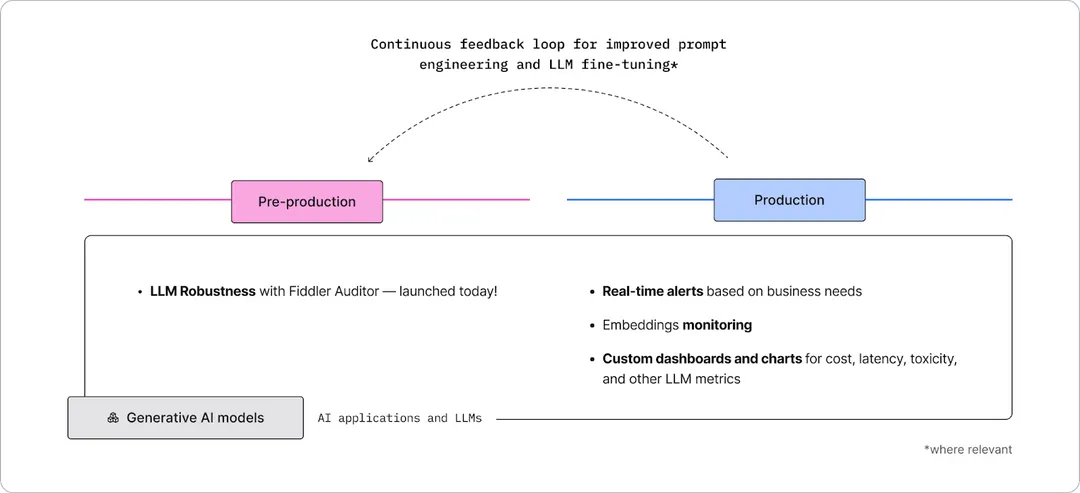
Pre-production Workflow:
Robust evaluation of prompts and models with Fiddler Auditor
We are thrilled to launch Fiddler Auditor today to ensure LLMs perform in a safe and correct fashion.
Fiddler Auditor is the first robustness library that leverages LLMs to evaluate robustness of other LLMs. Testing the robustness of LLMs in pre-production is a critical step in LLMOps. It helps identify weaknesses that can result in hallucinations, generate harmful or biased responses, and expose private information. ML and software application teams can now utilize the Auditor to test model robustness by applying perturbations, including adversarial examples, out-of-distribution inputs, and linguistic variations, and obtain a report to analyze the outputs generated by the LLM.
A practitioner can evaluate LLMs from OpenAI, Anthropic, and Cohere using the Fiddler Auditor and find areas to improve correctness and performance while minimizing hallucinations. In the example below, we tested OpenAI’s test-davinci-003 model with the following prompt and the best output it should generate when prompted:

Then, we entered five perturbations with linguistic variations, and only one of them generated the desired output as seen in the report below. If the LLM were released for public use as is, users would lose trust in it as the model generates hallucinations for simple paraphrasing, and users could potentially be harmed had they acted on the output generated.

The Fiddler Auditor is on GitHub. Don’t forget to give us a star if you enjoy using it! ⭐
Production Workflow:
Continuous monitoring to ensure optimal experience
Transitioning into production requires continuous monitoring to ensure optimal performance. Earlier this year, we announced how vector monitoring in the Fiddler AI Observability platform can monitor LLM-based embeddings generated by OpenAI, Anthropic, Cohere, and embeddings from other LLMs with a minimal integration effort. Our clustering-based multivariate drift detection algorithm is a novel method for measuring data drift in natural language processing (NLP) and computer vision (CV) models.
ML teams can track and share LLM metrics like model performance, latency, toxicity, costs, and other LLM-specific metrics in real-time using custom dashboards and charts. Metrics like toxicity are calculated by using methods from HuggingFace. Early warnings from flexible model monitoring alerts cut through the noise and help teams prioritize on business-critical issues.

Improving LLM performance using root cause analysis
Organizations need in-depth visibility into their AI solutions to help improve user satisfaction. Through slice & explain, ML teams can get a 360° view into the performance of their AI solutions, helping them refine prompt context, and gain valuable inputs for fine-tuning models.
Fiddler AI Observability: A Unified Platform for ML and Generative AI

With these new product enhancements, the Fiddler AI Observability platform is a full stack platform for predictive and generative AI models. ML/AI and engineering teams can standardize their practices for both LLMOps and MLOps through model monitoring, explainable AI, analytics, fairness, and safety.
We continue our unwavering mission to partner with companies in their AI journey to build trust into AI. Our product and data science teams have been working with companies that are defining ways to operationalize AI beyond predictive models and successfully implement generative AI models to deliver high performance AI, reduce costs, and be responsible with model governance.
We look forward to building more capabilities to help companies standardize their LLMOps and MLOps.
