
The future of Generative AI (GenAI) is bright as it continues to help enterprises enhance their competitive advantage, boost operational efficiency, and reduce costs. With AI Observability, enterprises can ensure deployed large language model (LLM) applications are monitored for correctness, safety, and privacy, among other LLM metrics.
NVIDIA’s NeMo Guardrails + Fiddler AI Observability for accurate, safe, and secure LLM applications
Together, NVIDIA’s NeMo Guardrails and the Fiddler AI Observability Platform provide a comprehensive solution for enterprises to gain the most value from their highly accurate and safe LLM deployments while derisking adverse outcomes from unintended LLM responses.
NeMo Guardrails is an open-source toolkit designed to add programmable guardrails to LLM applications, allowing developers and engineers to control and mitigate risks in real-time conversations. The Fiddler AI Observability Platform provides rich insights into prompts and responses, enabling the improvement of LLMOps. It complements NeMo Guardrails and helps to:
- monitor key LLM metrics, including hallucinations (faithfulness, answer relevance, coherence)
- safety (PII, toxicity, jailbreak)
- operational metrics (cost, latency, data quality)
In this blog, we provide details on how application engineers and developers can deploy LLM applications with NeMo Guardrails and monitor NeMo Guardrails’ metrics as well as LLM metrics in the Fiddler AI Observability Platform.
How the NeMo Guardrails and Fiddler Integration Works
NeMo Guardrails provides a rich set of rails to moderate and safeguard conversations. Developers can choose to define the behavior of the LLM-based application on specific topics and prevent it from engaging in discussions on unwanted topics. Additionally, developers can steer the LLM to follow pre-defined conversational paths to ensure reliable and trustworthy dialog [1].
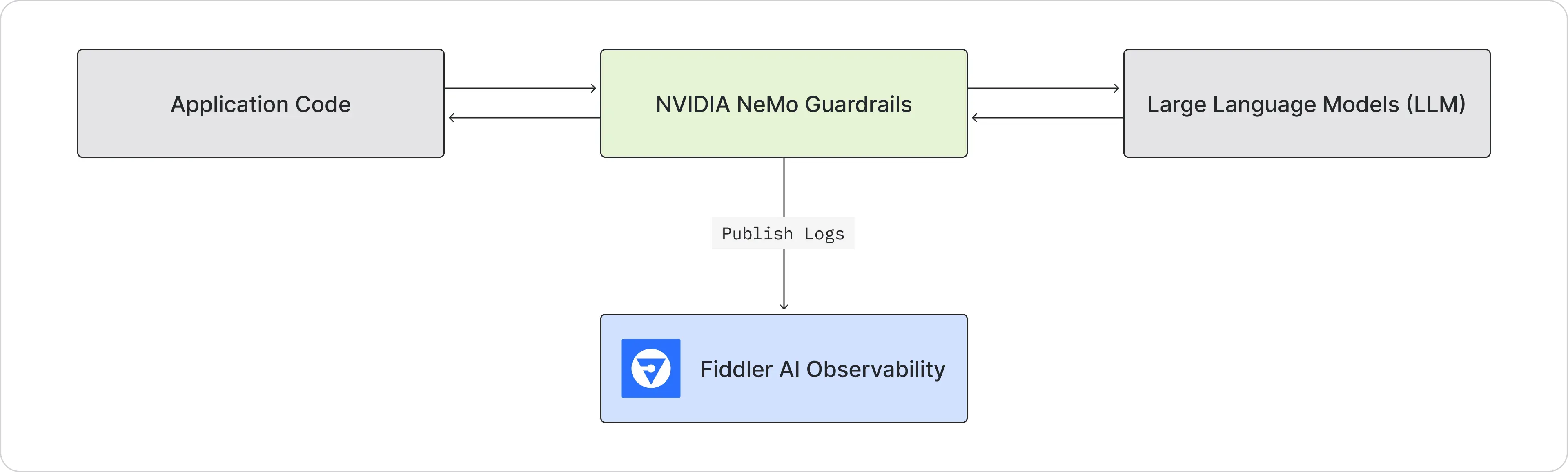
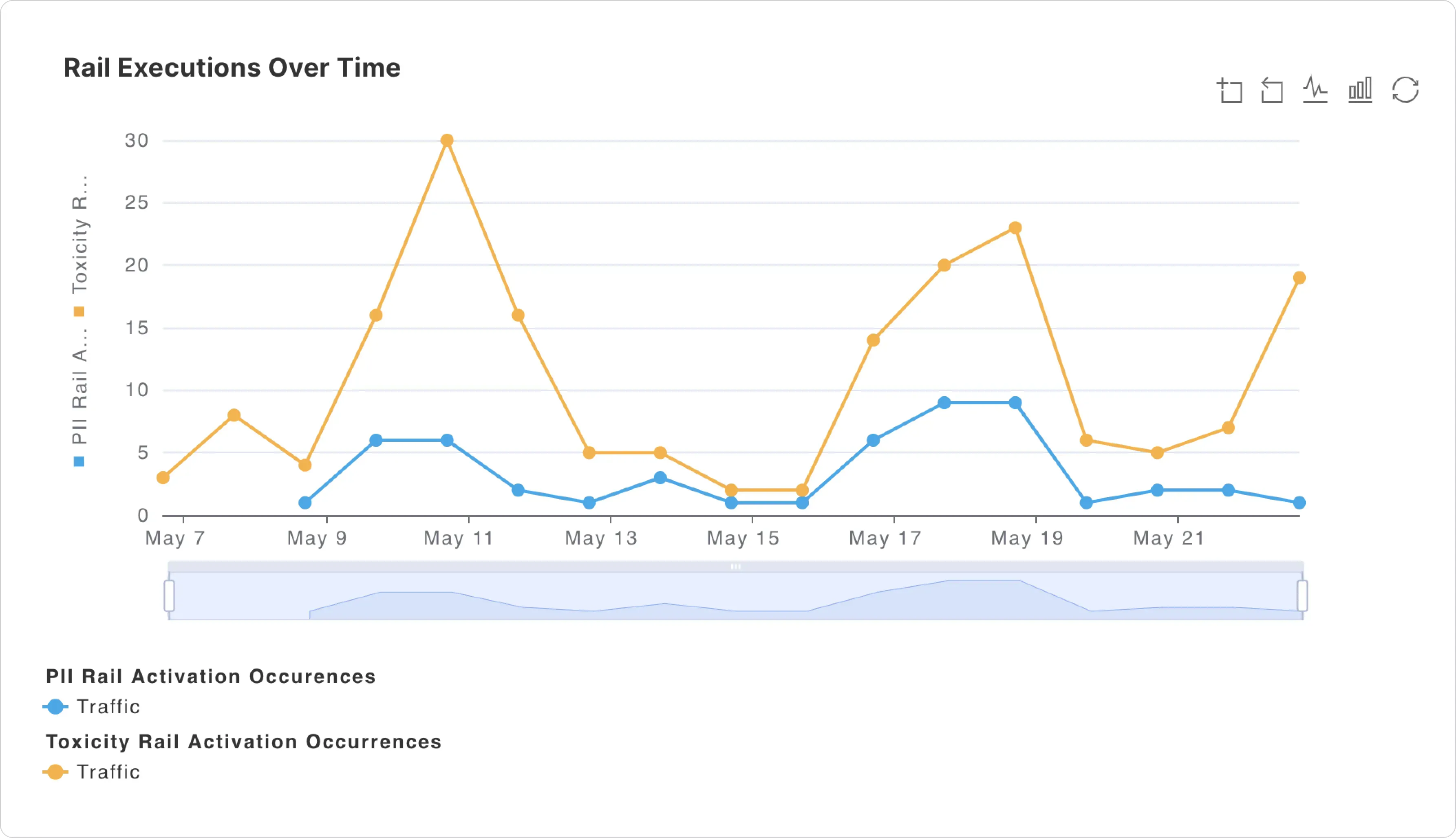
Once integrated, the prompts, responses, metadata, and the rails executed in NeMo Guardrails for each conversation can be published to Fiddler. This enables developers to observe and gain insights into the rails executed in a conversation from NeMo Guardrails. Developers can also define a rich set of alerts on the rails information published to Fiddler. In addition to rails information, the Fiddler AI Observability Platform also provides a wide variety of metrics to detect hallucination, drift, safety, and operational issues. Developers obtain rich insights into their rails and LLM metrics using Fiddler custom dashboards and reports, enabling them to perform deep root cause analysis to pinpoint and address issues.
Set up NeMo Guardrails Fiddler Integration
This section dives into details on how to publish logs from NVIDIA NeMo Guardrails to the Fiddler platform.
Prerequisites
- Access to the LLM provider key
- Access to the Fiddler deployment
- Python environment for running the application code
You can begin by setting up your Python environment. Ensure you have the following packages installed from PyPI:
pandas
fiddler-client
nemoguardrails
nest-asyncioIntegration Code Walk-through
Then once installed, go ahead and import the packages.
import os
import logging
import pandas as pd
import fiddler as fdl
import nest_asyncio
from nemoguardrails import LLMRails, RailsConfigYou’ll also want to set the OpenAI API key as an environment variable.
os.environ['OPENAI_API_KEY'] = '' # Add your OpenAI API key hereGreat, you’re done getting set up.
Below is a snippet for the NeMo Guardrails Fiddler integration code. Just define the FiddlerLogger class in your environment and you can start sending your rails output to the Fiddler AI Observability Platform.
class FiddlerLogger:
def __init__(self, project_name, model_name, decisions):
self.project_name = project_name
self.model_name = model_name
self.decisions = decisions
self.project = None
self.model = None
try:
self.project = fdl.Project.from_name(self.project_name)
except:
pass
try:
self.model = fdl.Model.from_name(
project_id=self.project.id,
name=self.model_name
)
except:
pass
self.logger = self.configure_logger()
def configure_logger(self):
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
class FiddlerHandler(logging.Handler):
def __init__(self, level, project, model, decisions, preprocess_function):
super().__init__(level=level)
self.project = project
self.model = model
self.decisions = decisions
self.preprocess_function = preprocess_function
def emit(self, record):
log_entry = self.preprocess_function(record.__dict__['payload'])
self.send_to_fiddler(log_entry)
def send_to_fiddler(self, log_entry):
self.model.publish([log_entry])
handler = FiddlerHandler(
level=logging.INFO,
project=self.project,
model=self.model,
decisions=self.decisions,
preprocess_function=self.preprocess_for_fiddler
)
for hdlr in logger.handlers:
logger.removeHandler(hdlr)
logger.addHandler(handler)
return logger
def preprocess_for_fiddler(self, record):
last_user_message = record.output_data["last_user_message"]
last_bot_message = record.output_data["last_bot_message"]
log_entry = {
"last_user_message": last_user_message,
"last_bot_message": last_bot_message
}
for rail in record.log.activated_rails:
sanitized_rail_name = rail.name.replace(" ", "_")
for decision in self.decisions:
sanitized_decision_name = decision.replace(" ", "_")
log_entry[sanitized_rail_name + "_" + sanitized_decision_name] = 1 if decision in rail.decisions else 0
return log_entry
def generate_fiddler_model(self, rail_names):
project = fdl.Project(name=self.project_name)
project.create()
self.project = project
rail_column_names = []
for rail_name in rail_names:
sanitized_rail_name = rail_name.replace(" ", "_")
for decision in self.decisions:
sanitized_decision_name = decision.replace(" ", "_")
rail_column_names.append(sanitized_rail_name + "_" + sanitized_decision_name)
schema = fdl.ModelSchema(
columns=[
fdl.schemas.model_schema.Column(name='last_user_message', data_type=fdl.DataType.STRING),
fdl.schemas.model_schema.Column(name='last_bot_message', data_type=fdl.DataType.STRING)
] + [
fdl.schemas.model_schema.Column(name=rail_column_name, data_type=fdl.DataType.INTEGER, min=0, max=1) for rail_column_name in rail_column_names
]
)
spec = fdl.ModelSpec(
inputs=['last_user_message'],
outputs=['last_bot_message'],
metadata=rail_column_names
)
task = fdl.ModelTask.LLM
model = fdl.Model(
name=self.model_name,
project_id=project.id,
schema=schema,
spec=spec,
task=task
)
model.create()
self.model = model
self.logger = self.configure_logger()
def log_to_fiddler(self, record):
self.logger.info("Logging event to Fiddler", extra={'payload': record})Now you’re ready to initialize the logger. Set up your rails object and make sure to create an options dictionary as shown below to ensure Guardrails produces the necessary logs for you to send to Fiddler.
config_path = "/path/to/config/dir/"
config = RailsConfig.from_path(config_path)
rails = LLMRails(config)
options = {
"output_vars": True,
"log": {
"activated_rails": True
},
}Now you can connect to Fiddler. Obtain a Fiddler URL and API token from your Fiddler administrator and run the code below.
fdl.init(
url='', # Add your Fiddler URL here
token='' # Add your Fiddler API token here
)You’re ready to create a FiddlerLogger object. Here, you’ll define the project and model on the Fiddler platform to which you want to send data.
Additionally, you’ll specify a list of decisions, which are the actions within your rails that you’re interested in tracking. Any time one of these decisions gets activated in a rail, it will get flagged within Fiddler.
logger = FiddlerLogger(
project_name='rails_project',
model_name='rails_model',
decisions=[
'execute generate_user_intent',
'execute generate_next_step',
'execute retrieve_relevant_chunks',
'execute generate_bot_message'
]
)Optionally, you can generate a Fiddler model using the FiddlerLogger class. If you’d rather go ahead and create your own model, feel free. But if you’re looking to get started with a jumping-off point, run the code below.
Here, rail_names is the list of rails you’re interested in tracking decisions for.
logger.generate_fiddler_model(
rail_names=[
'dummy_input_rail',
'generate_user_intent',
'generate_next_step',
'generate_bot_message',
'dummy_output_rail'
],
)You’re now ready to start sending data to Fiddler. Run rails.generate and make sure to pass in both the prompt (in messages) and the options dictionary you created earlier.
Then just pass the output of that call into the logger’s log_to_fiddler method.
nest_asyncio.apply()
messages=[{
"role": "user",
"content": "What can you do for me?"
}]
output = rails.generate(
messages=messages,
options=options
)
logger.log_to_fiddler(output)That’s it! Your Guardrails output will now be captured by Fiddler.
Summary
Enterprises can fully leverage the benefits of GenAI by addressing risks in LLMs, and operationalizing accurate, safe, and secure LLM applications. By integrating NVIDIA NeMo Guardrails with the Fiddler AI Observability Platform, application engineers and developers are now equipped to guide real-time conversations, as well as monitor and analyze data flowing from NeMo Guardrails into Fiddler. This integration ensures comprehensive oversight and enhanced control over their LLM applications.
Experience Fiddler LLM Observability in action with a guided product tour.
—
References
[1] https://docs.nvidia.com/nemo/guardrails/introduction.html#overview